一、微服务(microservices)
近几年,微服这个词闯入了我们的实线范围。在百度与谷歌中随便搜一搜也有几千万条的结果。那么,什么是微服务 呢?微服务的概念是怎么产生的呢? 我们就来了解一下Go语言与微服务的千丝万缕与来龙去脉。
什么是微服务?
在介绍微服务时,首先得先理解什么是微服务,顾名思义,微服务得从两个方面去理解,什么是”微”、什么是”服 务”?
微(micro) 狭义来讲就是体积小,著名的”2 pizza 团队”很好的诠释了这一解释(2 pizza 团队最早是亚马逊 CEO
Bezos提出来的,意思是说单个服务的设计,所有参与人从设计、开发、测试、运维所有人加起来 只需要2个披萨 就够了 )。
服务(service) 一定要区别于系统,服务一个或者一组相对较小且独立的功能单元,是用户可以感知最小功能 集。
那么广义上来讲,微服务是一种分布式系统解决方案,推动细粒度服务的使用,这些服务协同工作。
微服务这个概念的由来?
据说,早在2011年5月,在威尼斯附近的软件架构师讨论会上,就有人提出了微服务架构设计的概念,用它来描述 与会者所见的一种通用的架构设计风格。时隔一年之后,在同一个讨论会上,大家决定将这种架构设计风格用微服 务架构来表示。
起初,对微服务的概念,没有一个明确的定义,大家只能从各自的角度说出了微服务的理解和看法。 有人把微服务 理解为一种细粒度SOA(service-oriented Architecture,面向服务架构),一种轻量级的组件化的小型SOA。
在2014年3月,詹姆斯·刘易斯(James Lewis)与马丁·福勒(Martin Fowler)所发表的一篇博客中,总结了微服 务架构设计的一些共同特点,这应该是一个对微服务比较全面的描述。
原文链接 https://martinfowler.com/articles/microservices.html
这篇文章中认为:“简而言之,微服务架构风格是将单个应用程序作为一组小型服务开发的方法,每个服务程序都 在自己的进程中运行,并与轻量级机制(通常是HTTP资源API)进行通信。这些服务是围绕业务功能构建的。可以 通过全自动部署机器独立部署。这些服务器可以用不同的编程语言编写,使用不同的数据存储技术,并尽量不用集 中式方式进行管理”
微服务与微服务框架
在这里我们可能混淆了一个点,那就是微服务和微服务架构,这应该是两个不同的概念,而我们平时说道的微服务 可能就已经包含了这两个概念了,所以我们要把它们说清楚以免我们很纠结。微服务架构是一种设计方法,而微服 务这是应该指使用这种方法而设计的一个应用。所以我们必要对微服务的概念做出一个比较明确的定义。
微服务框架是将复杂的系统使用组件化的方式进行拆分,并使用轻量级通讯方式进行整合的一种设计方法。
微服务是通过这种架构设计方法拆分出来的一个独立的组件化的小应用。
微服务架构定义的精髓,可以用一句话来描述,那就是“分而治之,合而用之”。
将复杂的系统进行拆分的方法,就是“分而治之”。分而治之,可以让复杂的事情变的简单,这很符合我们平时处理 问题的方法。
使用轻量级通讯等方式进行整合的设计,就是“合而用之”的方法,合而用之可以让微小的力量变动强大。
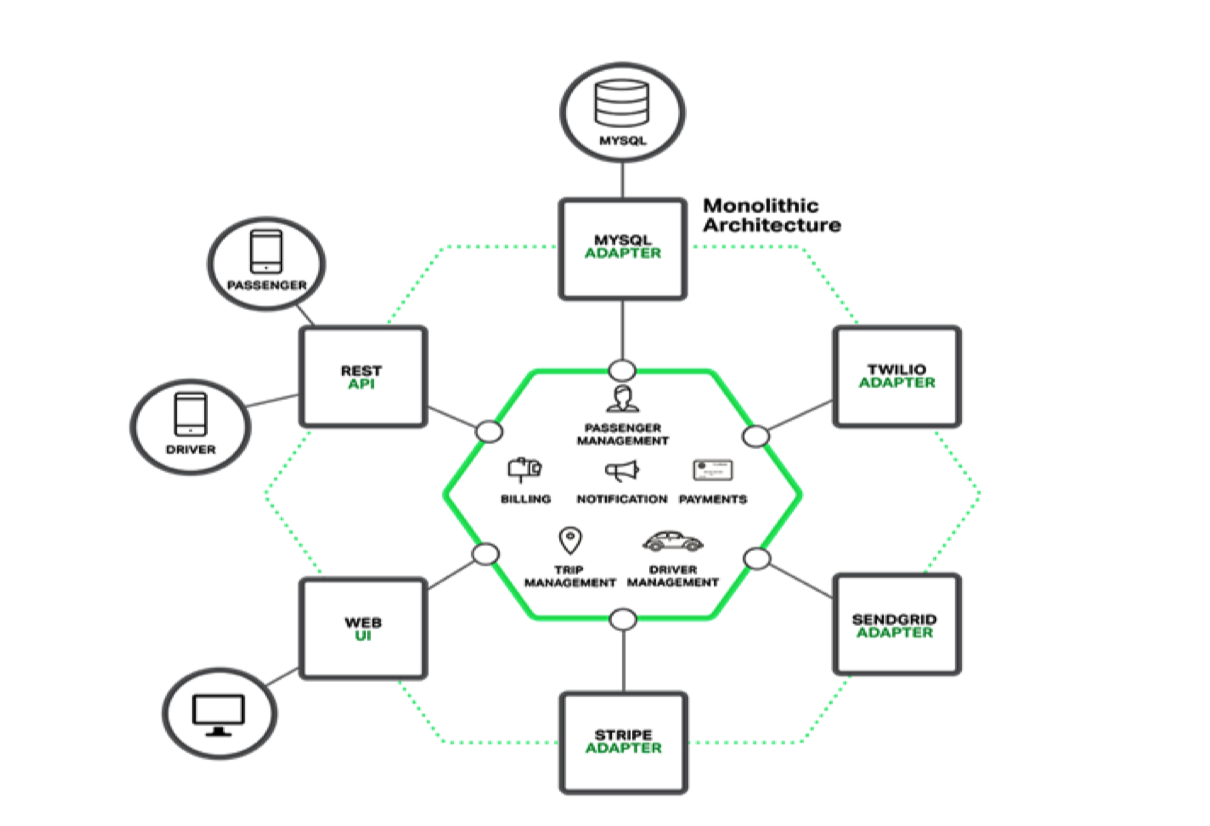
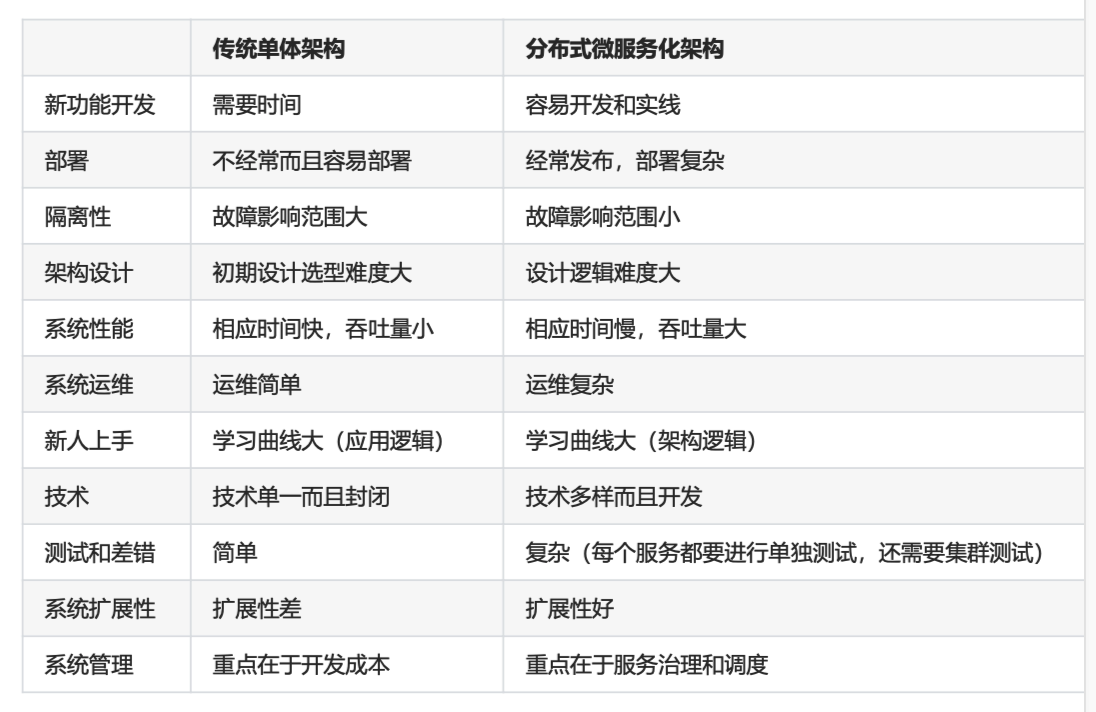
微服务架构和整体式架构的区别?
开发单体式(整体式)应用的不足之处
三层架构(MVC)的具体内容如下:
表示层(view): 用户使用应用程序时,看到的、听见的、输入的或者交互的部分。
业务逻辑层(controller): 根据用户输入的信息,进行逻辑计算或者业务处理的部分。
数据访问层(model): 关注有效地操作原始数据的部分,如将数据存储到存储介质(如数据库、文件系统)及 从存储介质中读取数据等。
虽然现在程序被分成了三层,但只是逻辑上的分层,并不是物理上的分层。也就是说,对不同层的代码而言,经过 编译、打包和部署后,所有的代码最终还是运行在同一个进程中。而这,就是所谓的单块架构。
单体架构在规模比较小的情况下工作情况良好,但是随着系统规模的扩大,它暴露出来的问题也越来越多,主要有 以下几点:
复杂性逐渐变高
比如有的项目有几十万行代码,各个模块之间区别比较模糊,逻辑比较混乱,代码越多复杂性越高,越难解决遇到 的问题。
技术债务逐渐上升
公司的人员流动是再正常不过的事情,有的员工在离职之前,疏于代码质量的自我管束,导致留下来很多坑,由于 单体项目代码量庞大的惊人,留下的坑很难被发觉,这就给新来的员工带来很大的烦恼,人员流动越大所留下的坑 越多,也就是所谓的技术债务越来越多。
维护成本大 当应用程序的功能越来越多、团队越来越大时,沟通成本、管理成本显著增加。当出现 bug 时,可能引起 bug 的 原因组合越来越多,导致分析、定位和修复的成本增加;并且在对全局功能缺乏深度理解的情况下,容易在修复 bug 时引入新的 bug。
持续交付周期长
构建和部署时间会随着功能的增多而增加,任何细微的修改都会触发部署流水线。新人培养周期长:新成员了解背 景、熟悉业务和配置环境的时间越来越长。
技术选型成本高
单块架构倾向于采用统一的技术平台或方案来解决所有问题,如果后续想引入新的技术或框架,成本和风险都很 大。
可扩展性差
随着功能的增加,垂直扩展的成本将会越来越大;而对于水平扩展而言,因为所有代码都运行在同一个进程,没办 法做到针对应用程序的部分功能做独立的扩展。
微服务架构的特性
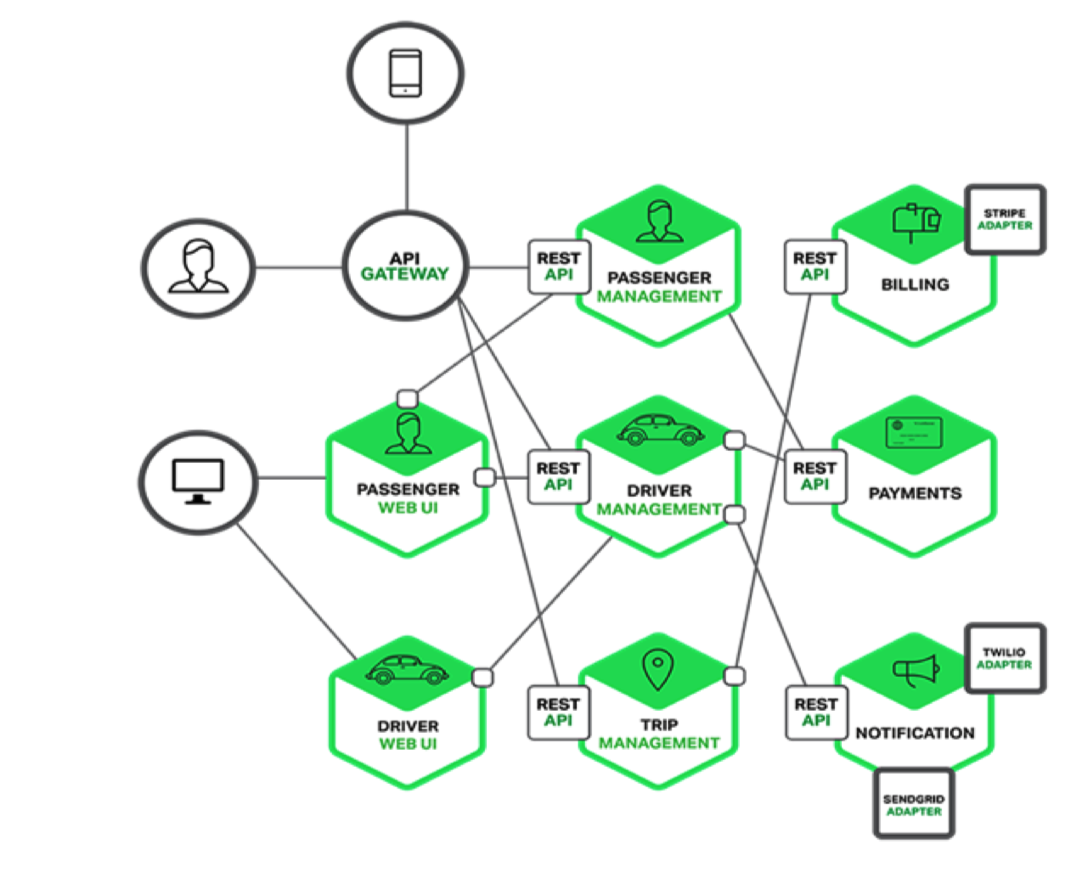
单一职责
微服务架构中的每个服务,都是具有业务逻辑的,符合高内聚、低耦合原则以及单一职责原则的单元,不同的服务 通过“管道”的方式灵活组合,从而构建出庞大的系统。
轻量级通信
服务之间通过轻量级的通信机制实现互通互联,而所谓的轻量级,通常指语言无关、平台无关的交互方式。
对于轻量级通信的格式而言,我们熟悉的 XML 和 JSON,它们是语言无关、平台无关的;对于通信的协议而言,通 常基于 HTTP,能让服务间的通信变得标准化、无状态化。目前大家熟悉的 REST(Representational State Transfer)是实现服务间互相协作的轻量级通信机制之一。使用轻量级通信机制,可以让团队选择更适合的语言、 工具或者平台来开发服务本身。
问:REST是什么和restful一样吗?
答:REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
独立性
每个服务在应用交付过程中,独立地开发、测试和部署。
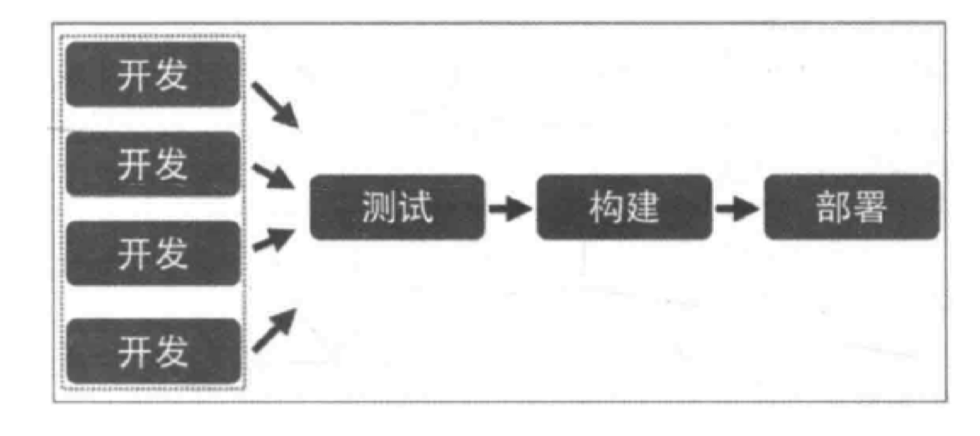
在单块架构中所有功能都在同一个代码库,功能的开发不具有独立性;当不同小组完成多个功能后,需要经过集成 和回归测试,测试过程也不具有独立性;当测试完成后,应用被构建成一个包,如果某个功能存在 bug,将导致整 个部署失败或者回滚。 在微服务架构中,每个服务都是独立的业务单元,与其他服务高度解耦,只需要改变当前服务本身,就可以完成独 立的开发、测试和部署。
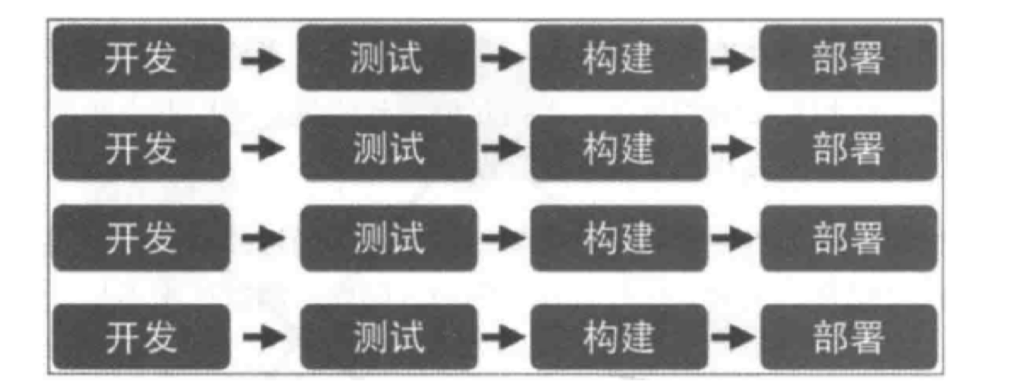
进程隔离
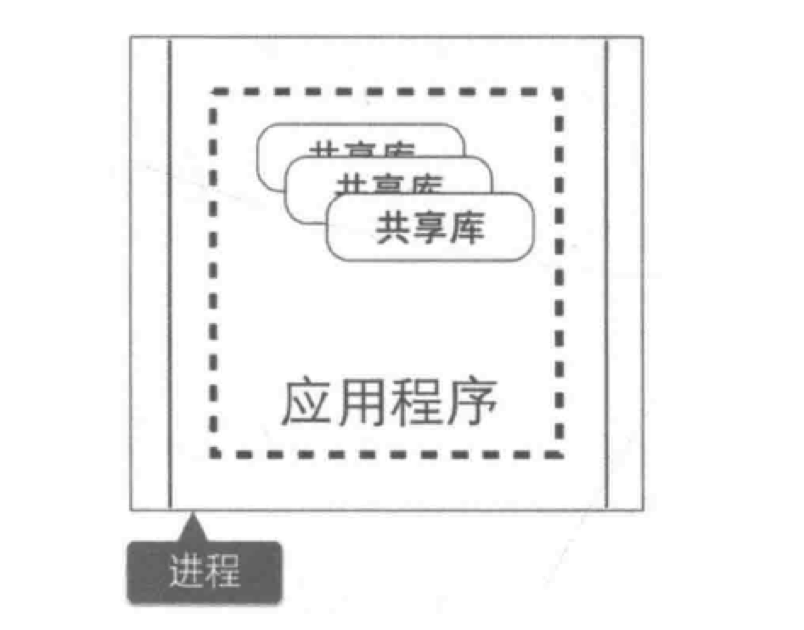
单块架构中,整个系统运行在同一个进程中,当应用进行部署时,必须停掉当前正在运行的应用,部署完成后再重 启进程,无法做到独立部署。
有时候我们会将重复的代码抽取出来封装成组件,在单块架构中,组件通常的形态叫做共享库(如 jar 包或者 DLL),但是当程序运行时,所有组件最终也会被加载到同一进程中运行。
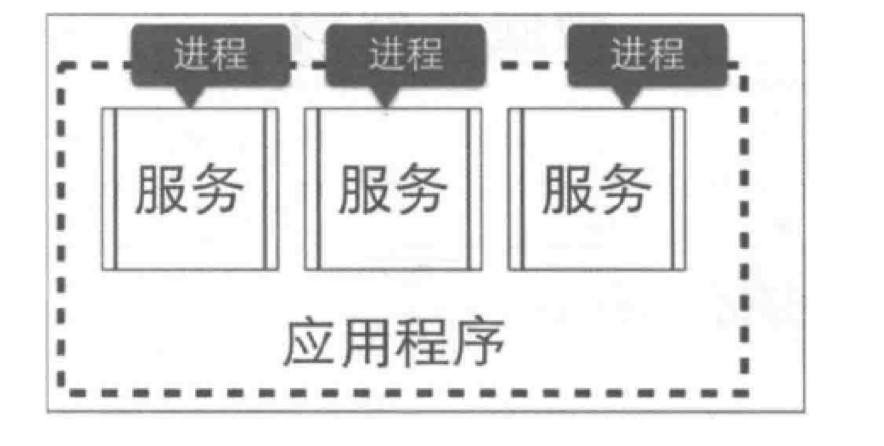
在微服务架构中,应用程序由多个服务组成,每个服务都是高度自治的独立业务实体,可以运行在独立的进程中, 不同的服务能非常容易地部署到不同的主机上。
微服务架构的缺点
运维要求较高
对于单体架构来讲,我们只需要维护好这一个项目就可以了,但是对于微服务架构来讲,由于项目是由多个微服务 构成的,每个模块出现问题都会造成整个项目运行出现异常,想要知道是哪个模块造成的问题往往是不容易的,因 为我们无法一步一步通过debug的方式来跟踪,这就对运维人员提出了很高的要求。
分布式的复杂性
对于单体架构来讲,我们可以不使用分布式,但是对于微服务架构来说,分布式几乎是必会用的技术,由于分布式 本身的复杂性,导致微服务架构也变得复杂起来。 接口调整成本高
比如,用户微服务是要被订单微服务和电影微服务所调用的,一旦用户微服务的接口发生大的变动,那么所有依赖 它的微服务都要做相应的调整,由于微服务可能非常多,那么调整接口所造成的成本将会明显提高。
重复劳动
对于单体架构来讲,如果某段业务被多个模块所共同使用,我们便可以抽象成一个工具类,被所有模块直接调用, 但是微服务却无法这样做,因为这个微服务的工具类是不能被其它微服务所直接调用的,从而我们便不得不在每个 微服务上都建这么一个工具类,从而导致代码的重复。
为什么使用微服务架构
开发简单
微服务架构将复杂系统进行拆分之后,让每个微服务应用都开放变得非常简单,没有太多的累赘。对于每一个开发 者来说,这无疑是一种解脱,因为再也不用进行繁重的劳动了,每天都在一种轻松愉快的氛围中工作,其效率也会 整备地提高
快速响应需求变化
一般的需求变化都来自于局部功能的改变,这种变化将落实到每个微服务上,二每个微服务的功能相对来说都非常 简单,更改起来非常容易,所以微服务非常是和敏捷开发方法,能够快速的影响业务的需求变化。
随时随地更新
一方面,微服务的部署和更新并不会影响全局系统的正常运行;另一方面,使用多实例的部署方法,可以做到一个 服务的重启和更新在不易察觉的情况下进行。所以每个服务任何时候都可以进行更新部署。
系统更加稳定可靠
微服务运行在一个高可用的分布式环境之中,有配套的监控和调度管理机制,并且还可以提供自由伸缩的管理,充 分保障了系统的稳定可靠性
二、Protobuf

protobuf是google旗下的一款平台无关,语言无关,可扩展的序列化结构数据格式。所以很适合用做数据存储和作 为不同应用,不同语言之间相互通信的数据交换格式,只要实现相同的协议格式即同一 proto文件被编译成不同的 语言版本,加入到各自的工程中去。这样不同语言就可以解析其他语言通过 protobuf序列化的数据。目前官网提 供了 C++,Python,JAVA,GO等语言的支持。google在2008年7月7号将其作为开源项目对外公布。
protoBuf简介
Google Protocol Buffer(简称 Protobuf)是一种轻便高效的结构化数据存储格式,平台无关、语言无关、可扩展, 可用于通讯协议和数据存储等领域。 数据交互的格式比较
数据交互xml、json、protobuf格式比较
1、json: 一般的web项目中,最流行的主要还是json。因为浏览器对于json数据支持非常好,有很多内建的函数支 持。
2、xml: 在webservice中应用最为广泛,但是相比于json,它的数据更加冗余,因为需要成对的闭合标签。json使 用了键值对的方式,不仅压缩了一定的数据空间,同时也具有可读性。
3、protobuf:是后起之秀,是谷歌开源的一种数据格式,适合高性能,对响应速度有要求的数据传输场景。因为 profobuf是二进制数据格式,需要编码和解码。数据本身不具有可读性。因此只能反序列化之后得到真正可读的数 据。
相对于其它protobuf更具有优势
1:序列化后体积相比Json和XML很小,适合网络传输
2:支持跨平台多语言 3:消息格式升级和兼容性还不错 4:序列化反序列化速度很快,快于Json的处理速速
protoBuf的优点
Protobuf 有如 XML,不过它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代 码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。只需使用 Protobuf 对数据结构 进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
它有一个非常棒的特性,即“向后”兼容性好,人们不必破坏已部署的、依靠“老”数据格式的程序就可以对数据结构 进行升级。
Protobuf 语义更清晰,无需类似 XML 解析器的东西(因为 Protobuf 编译器会将 .proto 文件编译生成对应的数据 访问类以对 Protobuf 数据进行序列化、反序列化操作)。使用 Protobuf 无需学习复杂的文档对象模型, Protobuf 的编程模式比较友好,简单易学,同时它拥有良好的文档和示例,对于喜欢简单事物的人们而言, Protobuf 比其他的技术更加有吸引力。
ProtoBuf 的不足
Protobuf 与 XML 相比也有不足之处。它功能简单,无法用来表示复杂的概念。 XML 已经成为多种行业标准的编写工具,Protobuf 只是 Google 公司内部使用的工具,在通用性上还差很多。 由 于文本并不适合用来描述数据结构,所以 Protobuf 也不适合用来对基于文本的标记文档(如 HTML)建模。另 外,由于 XML 具有某种程度上的自解释性,它可以被人直接读取编辑,在这一点上 Protobuf 不行,它以二进制的 方式存储,除非你有 .proto 定义,否则你没法直接读出 Protobuf 的任何内容。
Protobuf安装
安装protoBuf
#下载 protoBuf:
$ git clone https://github.com/protocolbuffers/protobuf.git
#或者直接将压缩包拖入后解压
unzip protobuf.zip
#安装依赖库
$ sudo apt-get install autoconf dev -y
#安装
$ cd protobuf/
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
$ sudo ldconfig # 刷新共享库 很重要的一步啊 #安装的时候会比较卡 #成功后需要使用命令测试
$ protoc –h
获取proto包
#Go语言的proto API接口
$ go get -v -u github.com/golang/protobuf/proto
安装protoc-gen-go插件
它是一个 go程序,编译它之后将可执行文件复制到\bin目录。
#安装
$ go get -v -u github.com/golang/protobuf/protoc-gen-go
#编译
$ cd $GOPATH/src/github.com/golang/protobuf/protoc-gen-go/
$ go build
#将生成的 protoc-gen-go可执行文件,放在/bin目录下
$ sudo cp protoc-gen-go /bin/
protobuf的语法
要想使用 protobuf必须得先定义 proto文件。所以得先熟悉 protobuf的消息定义的相关语法。
定义一个消息类型
syntax = "proto3";
message PandaRequest {
string name = 1;
int32 shengao = 2;
repeated int32 tizhong = 3;
}
PandaRequest消息格式有3个字段,在消息中承载的数据分别对应于每一个字段。其中每个字段都有一个名字和 一种类型。
文件的第一行指定了你正在使用proto3语法:如果你没有指定这个,编译器会使用proto2。这个指定语法行必须 是文件的非空非注释的第一个行。
在上面的例子中,所有字段都是标量类型:两个整型(shengao和tizhong),一个string类型(name)。
Repeated 关键字表示重复的那么在go语言中用切片进行代表
正如上述文件格式,在消息定义中,每个字段都有唯一的一个标识符。
添加更多消息类型
在一个.proto文件中可以定义多个消息类型。在定义多个相关的消息的时候,这一点特别有用——例如,如果想定 义与SearchResponse消息类型对应的回复消息格式的话,你可以将它添加到相同的.proto文件中
syntax = "proto3";
message PandaRequest { string name = 1; int32 shengao = 2; int32 tizhong = 3; }
message PandaResponse { ...
}
从.proto文件生成了什么?
当用protocol buffer编译器来运行.proto文件时,编译器将生成所选择语言的代码,这些代码可以操作在.proto文 件中定义的消息类型,包括获取、设置字段值,将消息序列化到一个输出流中,以及从一个输入流中解析消息。
对C++来说,编译器会为每个.proto文件生成一个.h文件和一个.cc文件,.proto文件中的每一个消息有一个对应的 类。
对Python来说,有点不太一样——Python编译器为.proto文件中的每个消息类型生成一个含有静态描述符的模 块,,该模块与一个元类(metaclass)在运行时(runtime)被用来创建所需的Python数据访问类。
对go来说,编译器会为每个消息类型生成了一个.pd.go文件。
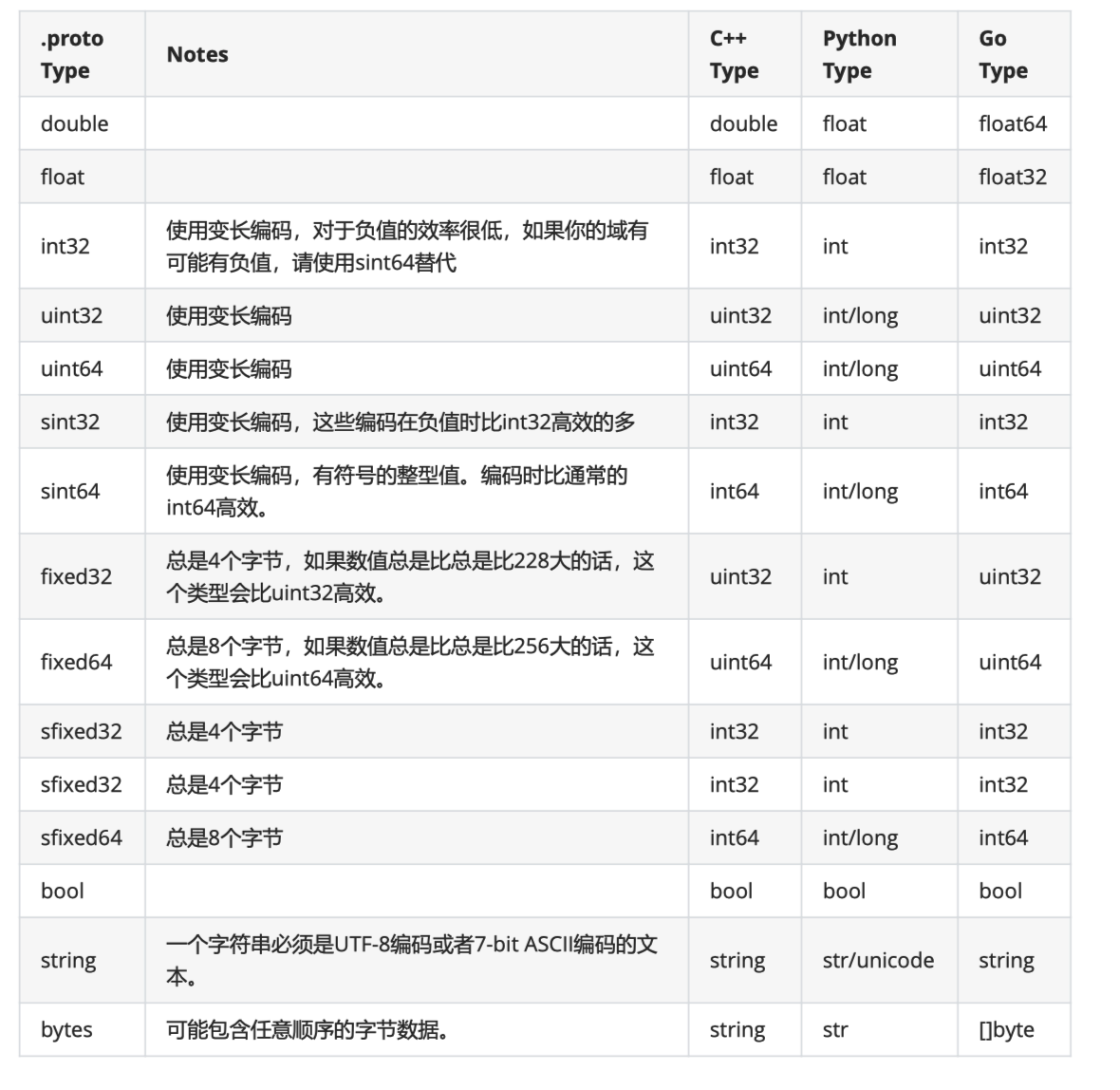
标准数据类型
一个标量消息字段可以含有一个如下的类型——该表格展示了定义于.proto文件中的类型,以及与之对应的、在自动生成的访问类中定义的类型:
默认值
当一个消息被解析的时候,如果被编码的信息不包含一个特定的元素,被解析的对象锁对应的域被设置位一个默认值,对于不同类型指定如下:
对于strings,默认是一个空string
对于bytes,默认是一个空的bytes
对于bools,默认是false
对于数值类型,默认是0
使用其他消息类型
你可以将其他消息类型用作字段类型。例如,假设在每一个PersonInfo消息中包含Person消息,此时可以在相同 的.proto文件中定义一个Result消息类型,然后在PersonInfo消息中指定一个Person类型的字段
message PersonInfo { repeated Person info = 1; } message Person {
string name = 1;
int32 shengao = 2;
repeated int32 tizhong = 3;
}
使用proto2消息类型
在你的proto3消息中导入proto2的消息类型也是可以的,反之亦然,然后proto2枚举不可以直接在proto3的标识 符中使用(如果仅仅在proto2消息中使用是可以的)。
嵌套类型
你可以在其他消息类型中定义、使用消息类型,在下面的例子中,Person消息就定义在PersonInfo消息内,如:
message PersonInfo {
message Person {
string name = 1;
int32 shengao = 2; r
epeated int32
tizhong = 3; }
repeated Person info = 1;
}
如果你想在它的父消息类型的外部重用这个消息类型,你需要以PersonInfo.Person的形式使用它,如:
message PersonMessage {
PersonInfo.Person info = 1;
}
当然,你也可以将消息嵌套任意多层,如:
message Grandpa {
// Level 0
message Father {
// Level 1 message son {
// Level 2 string name = 1;
int32 age = 2;
}
}
message Uncle {
// Level 1 message Son {
// Level 2 string name = 1;
int32 age = 2;
}
}
}
定义服务(Service)
如果想要将消息类型用在RPC(远程方法调用)系统中,可以在.proto文件中定义一个RPC服务接口,protocol buffer 编译器将会根据所选择的不同语言生成服务接口代码及存根。如,想要定义一个RPC服务并具有一个方法,该方法 能够接收 SearchRequest并返回一个SearchResponse,此时可以在.proto文件中进行如下定义:
service SearchService {
//rpc 服务的函数名 (传入参数)返回(返回参数)
rpc Search (SearchRequest)
returns (SearchResponse);
}
最直观的使用protocol buffer的RPC系统是gRPC一个由谷歌开发的语言和平台中的开源的RPC系统,gRPC在使用 protocl buffer时非常有效,如果使用特殊的protocol buffer插件可以直接为您从.proto文件中产生相关的RPC代 码。
如果你不想使用gRPC,也可以使用protocol buffer用于自己的RPC实现,你可以从proto2语言指南中找到更多信息
生成访问类(了解)
可以通过定义好的.proto文件来生成Java,Python,C++, Ruby, JavaNano, Objective-C,或者C# 代码,需要基 于.proto文件运行protocol buffer编译器protoc。如果你没有安装编译器,下载安装包并遵照README安装。对于 Go,你还需要安装一个特殊的代码生成器插件。你可以通过GitHub上的protobuf库找到安装过程
通过如下方式调用protocol编译器:
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR go_out=DST_DIR path/to/file.proto
--python_out=DST_DIR --
IMPORT_PATH声明了一个.proto文件所在的解析import具体目录。如果忽略该值,则使用当前目录。如果有多个 目录则可以多次调用–proto_path,它们将会顺序的被访问并执行导入。-I=IMPORT_PATH是–proto_path的简化 形式。
当然也可以提供一个或多个输出路径:
–cpp_out 在目标目录DST_DIR中产生C++代码,可以在C++代码生成参考中查看更多。
–python_out 在目标目录 DST_DIR 中产生Python代码,可以在Python代码生成参考中查看更多。
–go_out 在目标目录 DST_DIR 中产生Go代码,可以在GO代码生成参考中查看更多。 作为一个方便的拓展,如
果DST_DIR以.zip或者.jar结尾,编译器会将输出写到一个ZIP格式文件或者符合JAR标准的.jar文件中。注意如果输 出已经存在则会被覆盖,编译器还没有智能到可以追加文件。
- 你必须提议一个或多个.proto文件作为输入,多个.proto文件可以只指定一次。虽然文件路径是相对于当前目录 的,每个文件必须位于其IMPORT_PATH下,以便每个文件可以确定其规范的名称。
测试
protobuf的使用方法是将数据结构写入到 .proto文件中,使用 protoc编译器编译(间接使用了插件)得到一个新的 go包,里面包含 go中可以使用的数据结构和一些辅助方法。
编写 test.proto文件
$GOPATH/src/创建 myproto文件夹
$ cd $GOPATH/src/ $ make myproto
2.myproto文件夹中创建 test.proto文件 (protobuf协议文件
$ vim test.proto
文件内容
syntax = "proto3"; package myproto;
message Test {
string name = 1;
int32 stature = 2 ;
repeated int64 weight = 3 ;
string motto = 4;
}
3.编译 :执行
$ protoc --go_out=./ *.proto
生成 test.pb.go文件
4.使用 protobuf做数据格式转换
package main
import ( "fmt" "github.com/golang/protobuf/proto" "myproto" )
func main() {
test := &myproto.Test{
Name : "panda",
Stature : 180,
Weight : []int64{120,125,198,180,150,180},
Motto : "天行健,地势坤",
},
//将Struct test 转换成 protobuf
data,err:= proto.Marshal(test)
if err!=nil{ fmt.Println("转码失败",err) }
//得到一个新的Test结构体
newTest newtest:= &myproto.Test{}
//将data转换为test结构体
err = proto.Unmarshal(data,newtest)
if err!=nil { fmt.Println("转码失败",err) }
fmt.Println(newtest.String()) //得到name字段
fmt.Println("newtest->name",newtest.GetName())
fmt.Println("newtest->Stature",newtest.GetStature())
fmt.Println("newtest->Weight",newtest.GetWeight())
fmt.Println("newtest->Motto",newtest.GetMotto())
}